*Equal contribution
†Interns at Microsoft Research
‡Project Leads. Email: {yalia,jiaoyan}@microsoft.com
1Microsoft Research Asia 2Tsinghua University 3USTC 4Institute of Microelectronics, CAS
We present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose
VLM for action prediction by simple action quantization, we propose a componentized VLA architecture that
has a specialized action module conditioned on VLM output. We systematically study the design of the action
module and demonstrate the strong performance enhancement with diffusion action transformers for action
sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments
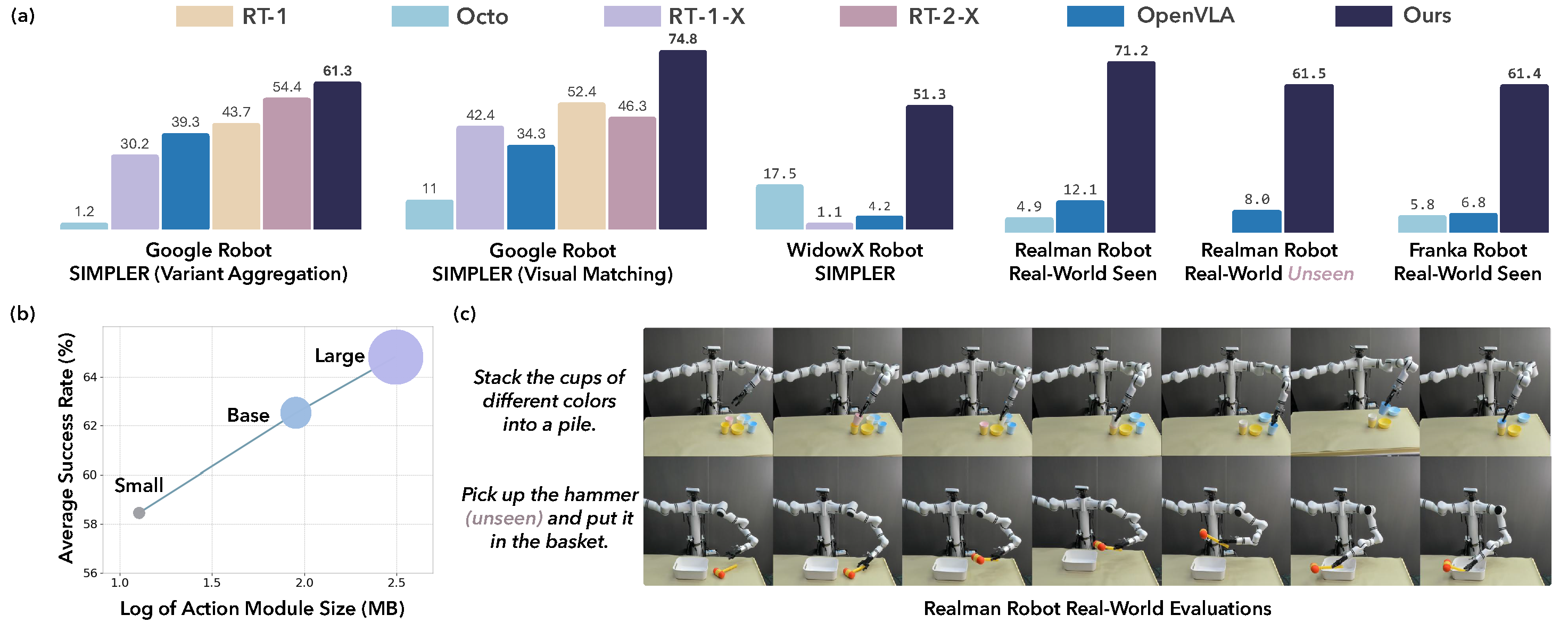
and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 4 robot
embodiments in simulation and real world shows that our model not only significantly surpasses existing VLAs
in task performance but also exhibits remarkable adaptation to new robots and generalization to unseen
objects and backgrounds. It exceeds the average success rates of OpenVLA which has a similar model size (7B)
with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the
large RT-2-X model (55B) by 18% absolute success rates in simulation.
Pretrained on 0.4M trajectories from the Open X-Embodiment dataset, the CogACT-VLA model quickly adapts to a new robot and environment with a few hundred trajectories.
It not only demonstrates significantly higher success rates than previous VLAs, but also exhibits remarkable object generalization capabilities and task robustness. (All videos are played at 8x speed with static frames (waiting for human’s next instruction input) removed for better demonstration. Raw videos can be found here.)
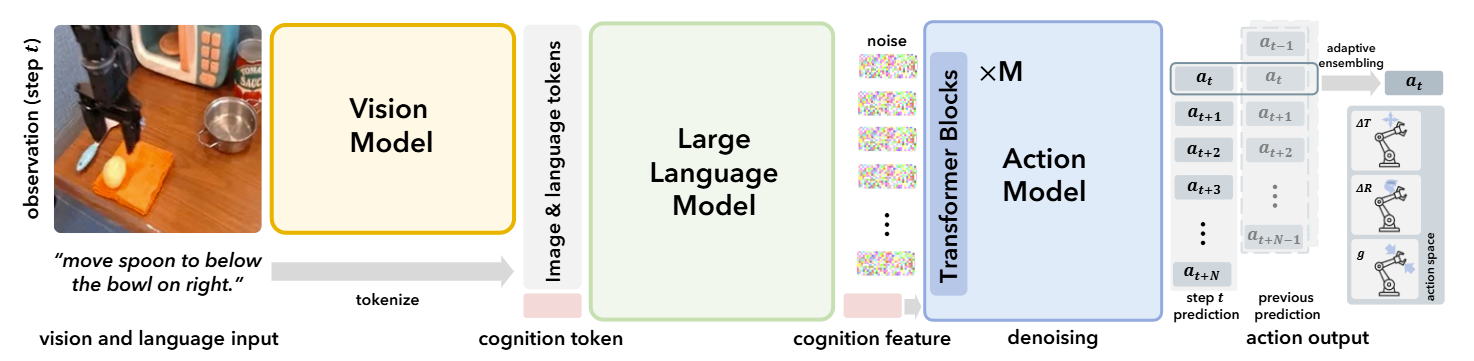
The CogACT Model
CogACT-VLA model architecture.
Our core idea is to leverage the cognitive information extracted by powerful VLMs to guide the action prediction of a specialized action module. CogACT-VLA has three componentized modules:
Vision Module: Processes raw image input into a set of perceptual tokens. It consists of
powerful vision transformers, DINOv2 and SigLIP, pretrained on Internet-scale image data, to
capture rich visual features and a comprehensive semantic understanding of the observations.
Language Module: Integrates visual information and language instructions and conducting
cognitive reasoning. Here, a LLAMA-2 is applied as the
backbone, which was trained on 2 trillion language tokens.
Action Module: Receives the cognition feature as an input condition to generate a series of
actions. Given that real-world physical actions are continuous and often multi-modal, we predict them
using a diffusion modeling process. To model complex and temporally-correlated actions, we apply a Diffusion Transformer (DiT) as a powerful backbone for
the action decoding process.
The Vision and Language modules are built upon a pretrained Prismatic-7B VLM and finetuned end-to-end with the Action module of up to 300M parameters. Our primary training data is a subset of the Open X-Embodiment
(OXE) dataset.
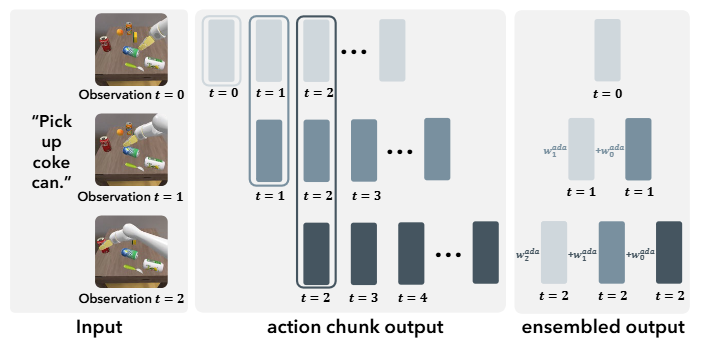
Adaptive ensemble strategy at inference.
During inference, our model predicts actions for multiple time steps. We propose an Adaptive Action Ensemble (AAE)
strategy which considers similarities between actions to be aggregated as shown in the above figure. This
approach avoids unreasonable aggregation of actions from different modes.
Experimental Results
Evaluation on SIMPLER
We first evaluate CogACT-VLA in the SIMPLER evaluation
environment. This simulation platform is designed to bridge the real-to-sim control and visual gap for the Google robot and the WidowX robot.
A strong correlation between the performance in SIMPLER and in the real world has been demonstrated by extensive evaluation of various VLA models. We compare CogACT-VLA with existing VLA models, including RT-1, RT-1-X, RT-2-X, Octo, and OpenVLA.
SIMPLER offers two evaluation settings: Visual Matching, which closely replicates the scene appearance of real-world tasks, and Variant Aggregations,
which introduces variations by modifying the background, lighting, distractors, table
textures, etc.
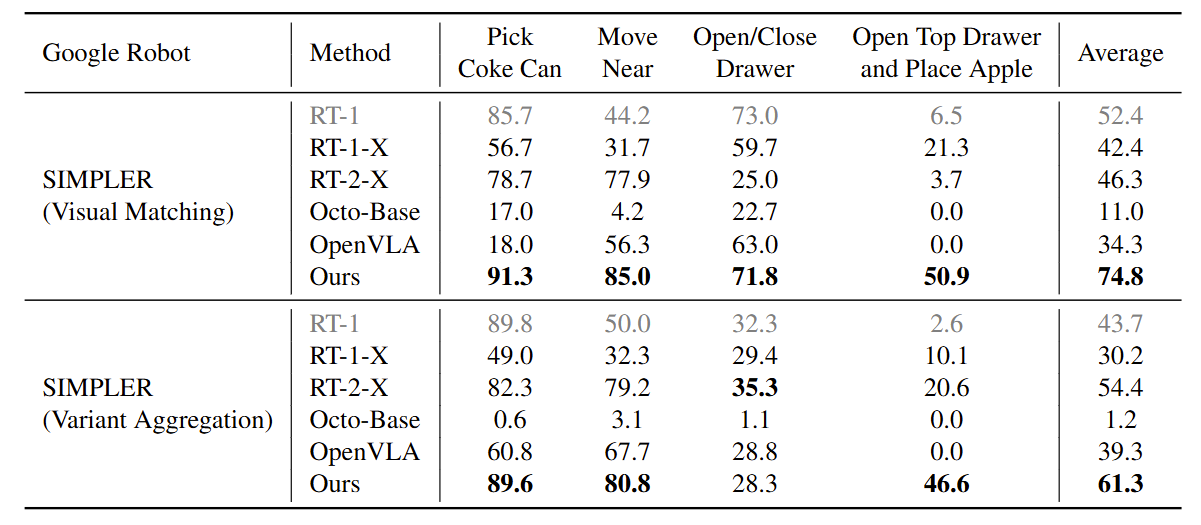
Evaluation and comparison on SIMPLER's Google robot tasks. All
models are trained on the OXE dataset (except for RT-1 which is trained only on OXE's Google
robot subset).
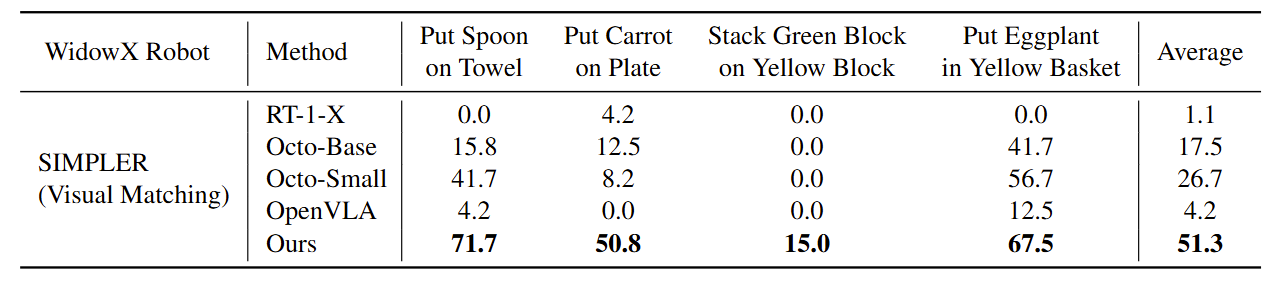
Evaluation and comparison on SIMPLER's WidowX robot tasks.
The results show that CogACT-VLA outperforms existing VLA models on both the Google robot and the WidowX robot tasks by a large margin.
Real-world Evaluation with Realman Robot
We evaluate CogACT-VLA with a Realman robot to
perform real-world tasks such as picking, stacking, and placing various colored objects. We collected a
dataset with 391 demonstrations in total and finetune different models. As shown in the table below, our model outperforms
OpenVLA and Octo-Base and achieves the highest average success rates.
Real-world evaluation with the Realman robot across three tasks, each with 20-40 trials of random configurations. All
models are pretrained on OXE and finetuned on the same data.
Generalization Capability - Unseen Tables with Unseen Distractors
We test our model on tables with various colors different from training data, thus
increasing the visual complexity of the task. Additionally, unseen objects are placed on the table as
distractors.
Generalization evaluation on the Realman Robot with unseen
tables and distractors.
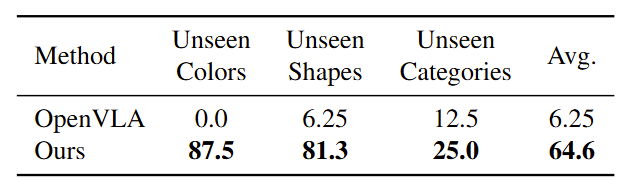
Generalization Capability - Unseen Colors, Shapes, and Categories.
We also test our model's ability to handle new color combinations of known objects, unfamiliar shapes like triangular and arched blocks, small cans, and cylindrical blocks for stacking
tasks, as well as new object categories such as hammers.
Generalization evaluation on the Realman Robot with unseen
colors, shapes, and categories.
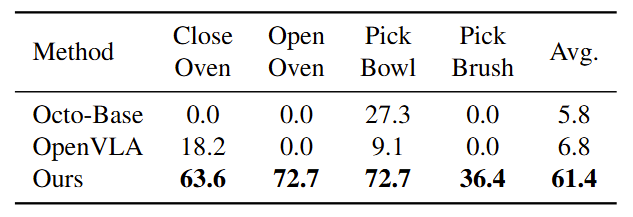
Real-World Evaluation with Franka Robot
We further use an Franka arm to evaluate our model's real-world
performance and compare it with previous methods. Similar to the experiments on the Realman robot, we collect training data and finetune different models for evaluation.
Real-world evaluation on the Franka Robot across four tasks. All models
are pretrained on OXE and finetuned on the same data.
Video Result Samples
Realman Robot
Examples of the Realman robot executing tasks involving
unseen objects, driven by our CogACT-VLA.
Examples of the Realman robot following multiple instructions in a row, driven by our CogACT-VLA.
Examples of the Realman robot executing tasks under dynamic disturbances, driven by our CogACT-VLA.
Franka Robot
Examples of the Franka robot executing tasks with our model.
Google Robot (in SIMPLER)
Examples of the Google robot executing tasks with our model in SIMPLER.
Pick Coke can.
Move Pepsi can near orange.
Close bottom drawer.
Open top drawer; Place apple into top drawer.
WidowX Robot (in SIMPLER)
Examples of the WidowX robot executing tasks with our model in SIMPLER.
Put carrot on plate.
Put the spoon on the towel.
Stack the green block on the yellow block.
Put eggplant into yellow basket.
Ablation Study
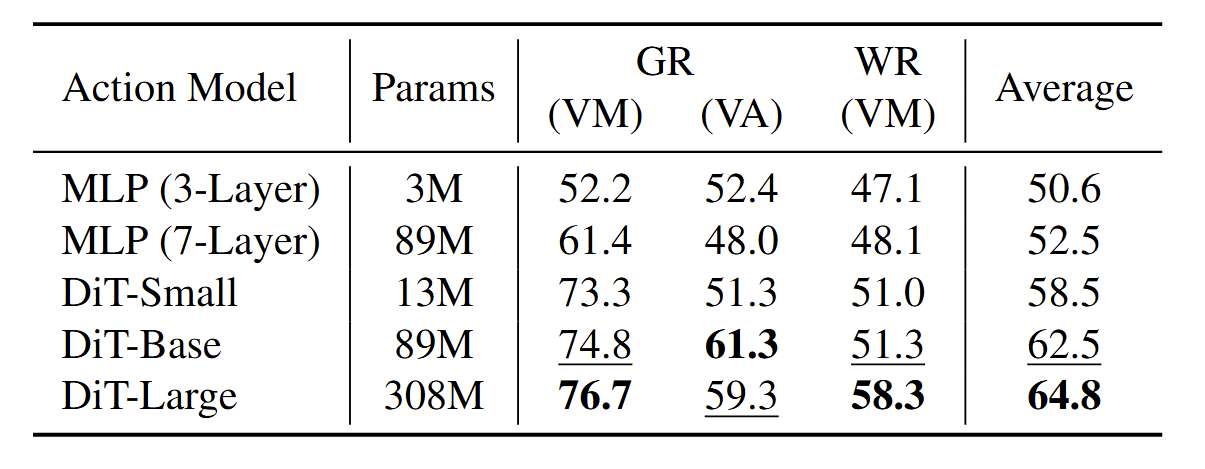
Action Model Scaling
We evaluate various action model architectures on Google Robot (GR) and WidowX Robot (WR) in SIMPLER. The architectures
examined include MLPs with depths of 3 and 7 layers, respectively, as well as a
series of DiT of varying sizes. The results show that both MLP and DiT structures show improved success rates with increased model
size, and DiT significantly outperforms MLP. Notably, DiT-Large achieves the highest average success
rate of 64.8%. The average success rate of transformers is approximately linearly related to the logarithm
of the model size, indicating a favorable scaling behavior of the action module with diffusion
transformers.
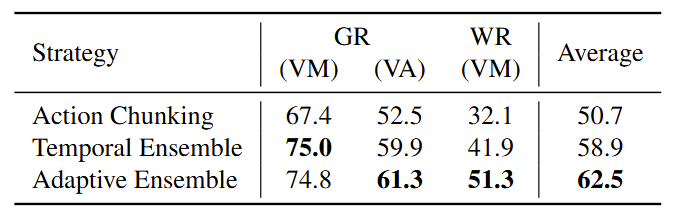
Adaptive Action Ensemble
We evaluate the proposed Adaptive Action Ensemble approach against the two ensemble strategies introduced in
ACT – Action Chunking and Temporal Ensemble. The results show that
our proposed Adaptive Ensemble outperforms others, and we attribute this to the efficacy of our adaptive similarity
weighting between the current and historical predictions.
BibTeX
@article{li2024cogact,
title={CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation},
author={Li, Qixiu and Liang, Yaobo and Wang, Zeyu and Luo, Lin and Chen, Xi and Liao, Mozheng and Wei, Fangyun and Deng, Yu and Xu, Sicheng and Zhang, Yizhong and others},
journal={arXiv preprint arXiv:2411.19650},
year={2024}
}